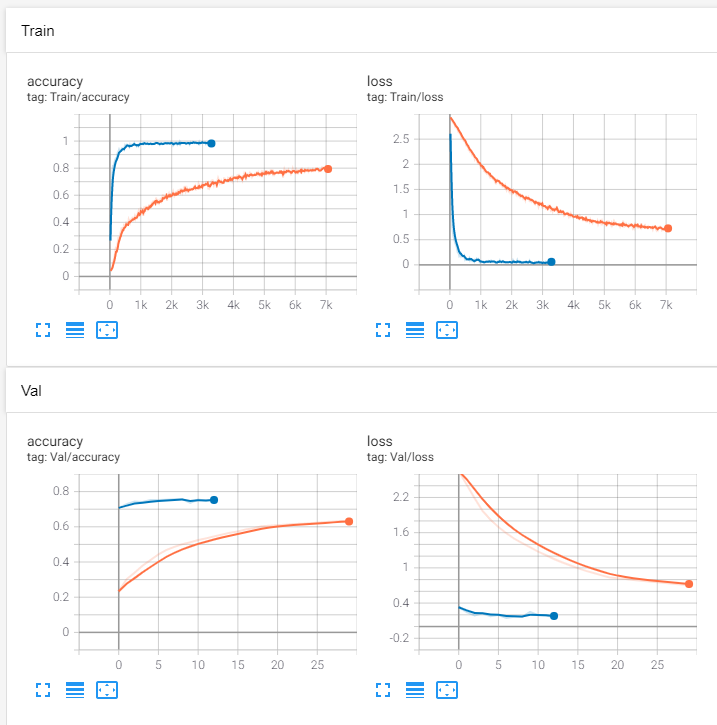
1주차 1. 판다스 프로파일링 설치하려고 했으나 계속 오류 발생했다. 서버를 지워버리고 다시 설치하니 오류가 사라졌다; 2. 데이터 셋에 사진 데이터를 집어넣긴했는데 라벨링 데이터를 함께 넣지는 못했다. 3. 라벨링데이터를 사진데이터와 합쳐서 구성할 수 있도록 Dataset을 구성했다. 2주차 첫째날 1. 내가 만든 기본 CNN 모델로 학습했더니 적중률이 10% 밖에 나오지 않았다. 옵티마이저는 아담사용, 학습률은 0.001, 배치사이즈 50 2. pretrained model인 efficient net b0를 가져다 썼더니 성능이 63프로로 올랐다. 옵티마이저는 SGD사용, 학습률은 0.001, 배치사이즈 64 3. inference를 하려고 했더니 에러가 발생했다. DataLoader worker (..