# sequence to sequence

seq to seq는 many to many인 방식이다.

위 예에서는 챗봇이 문장을 입력받아서 출력인 답변을 생성하는 구조이다.
이 방식은 인코더와 디코더로 구성되어있는데,
입력단어를 한개씩 받아들이는 RNN 부분을 인코더라고 하고,
출력단어를 한개씩 뱉는 RNN 부분을 디코더라고 한다.
인코더와 디코더는 서로 별개의 파라미터를 사용한다.
그리고 세부적인 내부 구현은 LSTM이 적용되어있다.
인코더에서의 최종 히든스테이트 벡터는,
디코더에서의 최초 히든스테이트 벡터가 된다.
디코더의 첫 입력으로는 start를 의미하는 토큰을 사전에 넣어두고 이를 입력으로 넣어준다.
그리고 마지막 최종출력인 end가 출력 될때 까지 디코더를 진행하게 된다.
만약 end가 출력되면 더이상 다음 디코더로 진행하지 않고 출력을 그만하는 것이다.
# attention
인코더에서 디코더로 히든 스테이트 벡터를 전달할때는,
인코더의 길이에 상관없이 그 히든 스테이트 벡터에 모든 정보를 우겨넣어 디코더로 전달해주게 된다.
하지만 LSTM의 특징에 따라서 인코더를 진행하는 동안
너무 오래전의 정보는 최종 히든 스테이트 벡터에서 없어지거나 소실 될 수 있다.
I go home 을 나는 집에 간다 라고 번역한다고 생각하자.
그런데 I는 가장 처음에 있던 입력이기 때문에 디코더로 전달되는 히든 스테이트 벡터에는
I라는 정보가 유실될 수 있다.
그래서 정작 첫번째 단어부터 제대로 출력을 얻지 못하는 상황이 생길 수 있다.
그래서 아예 입력을 거꾸로 home go I 순서로 넣어서 디코더상에서는
I에 대한 정보를 잘받도록 하는 방법이 있기도 하다.

attention 모듈은 디코더가 최종적인 히든 스테이트 벡터만 가져가도록 하는것이 아니라,
디코더가 필요로 하는 각 인코더 단계에서 발생한 히든 스테이트 벡터를 선별적으로 가져가는 구조이다.

각 단어가 인코더에 들어가게 되면,
인코더를 진행하면서 히든스테이트들이 만들어지게 되고,
최종적인 히든스테이트는 디코더로 전달된다.
디코더가 스타트 토큰을 워드임베딩된 상태로 전달받으면
디코더에서 처음으로 히든스테이트가 처음 발생하게 되고,
이 히든 스테이트는 인코더의 히든스테이트 각각과 내적 연산을 하게 된다.
그러면 어떤 유사도에 대한 정보가 나오게 될텐데,
이를 소프트맥스 연산을 수행해서 각각의 필요한 정도에 대한 비율을 얻는다.
그리고 그 비율을 이용하여 인코더에서의 히든 스테이트에 대한 각각의 가중 평균을 얻고
하나의 인코딩 벡터를 얻게 된다.
그 인코딩 벡터를 컨텍스트 벡터라고 한다.
전체적인 구조는 인코더로부터 최종적인 결과가 디코더로 전달되고,
디코더로부터의 히든 스테이트와 인코더로부터의 모든 히든 스테이트를 어텐션 모듈이 받아서,
어텐션 모듈은 인코더로부터의 가중 평균을 계산해서 컨텍스트 벡터를 얻는 것이다.

최종적으로는 어텐션 모듈의 컨텍스트 벡터와 디코더의 히든 스테이트를 concat해서
output layer의 입력으로 들어가게 되고, 나와야 하는 단어를 최종적으로 예측하게 된다.

다음 단어도 같은 방식으로 진행된다.


역전파 단계에서의 학습도 역방향으로 모두 일어난다.

# teacher forcing

학습시에는 디코더의 입력으로 이전 인코더가 생성한 단어가 아닌 ground truth를 넣어주게 되는데.
이런 방식을 teacher forcing이라고 한다.
그런데 이렇게 teacher forcing 방식으로만 학습하게 되면 실제 inference 할 때에는
이전 디코더의 출력을 받아들이면서 제대로 되지 않은 결과를 보여줄 수 있다.
그래서 학습에 후반부에는 teacher forcing을 하지 않고, 실제 이전 디코더가 만든 결과를
다음 디코더의 입력으로 넣어주는 방식도 있다.
# 유사도 구하는 여러가지 방법
디코더에서 얻은 히든 스테이트는 어텐션 모듈로 전달되어 각각의 인코더의 히든 스테이와 내적을해서
유사도를 구하게 되는데, 내적하는 방법 말고도 다른 방법들도 있다.


general 방식은 그냥 내적을 계산하는 것이 아니라,
중간에 어떤 가중치를 가지는 정사각행렬을 넣어서 계산하는 것이다.

concat 방식은 아예 fully connected layer을 만들어서 유사도를 구하는 것이다.
va가 행렬이 아니고 그냥 벡터인 이유는 최종적으로는 유사도인 스칼라 값이 나와야 하기 때문에
마지막 가중치로는 무조건 1차원 벡터를 사용해야 하기 때문이다.
그렇다면 general 방식에서의 정사각행렬의 가중치와
concat 방식에서의 fully connected layer의 weight는 어떻게 구하는 것일까?

역전파가 진행될때의 과정에서 함께 계산된다.
# attention의 장점과 특징
어텐션 모듈을 적용하면서 기계번역 분야에서의 성능을 굉장히 많이 올릴 수 있게 되었다.
디코더가 입력의 어떤 부분에 집중할지를 어텐션이 알려주기 때문이다.
병목현상을 해결할 수 있게 되었다.
기존에는 디코더가 인코더의 마지막 히든스테이트만 전달받았다면,
이제는 어텐션 모듈이 인코더에서 봐야할 히든 스테이트의 가중치를 정해주므로,
적절한 히든 스테이트를 참조 할 수 있게 된다.
그레디언트 배니싱문제 해결

어텐션이 없었다면 위처럼 모든 디코더와 모든 인코더를 진행하면서 학습을 진행해야 한다.
학습 과정에서 거리가 너무 먼 곳은 학습이 잘 되지 않을 문제가 있을텐데,
어텐션으로 인해 인코더로 향하는 지름길이 생기게 되었다.

그리고 어텐션은 해석 가능성을 제공해준다.
어텐션이 인코더의 어떤 입력에 집중했는지 알 수 있기 때문이다.
# attention pattern

어텐션 패턴을 보면 언어간에 참조해야 하는 단어 순서가 변경된 경우에도 잘 그 순서대로 참조하는 것을 볼 수 있다.

디코딩을 하는데 여러 입력을 봐야 하는 경우에도,
한개의 입력으로 여러개의 디코딩을 해야 하는 경우에도,
어텐션이 집중할 곳을 잘 지정해주고 있다.
# greedy decoding
시퀀스로서의 전체적인 문장의 확률값을 보는것이 아니라,
현재 타임 스텝에서 가장 좋아보이는 단어를 그때그때 선택하는 방식을
그리디 디코딩이라고 한다.

그런데 만약 다음 단어를 잘못 예측하게 되었다면,
뒤로 돌아갈 수 있는 방법이 없다.
그럼 이것을 어떻게 해결할까?

# exhautive search
입력문장을 x라고 하고 출력 문장을 y라고 하고,
출력 문장의 첫번째 단어를 y1이라고 하면,
p(y1|x)는 입력문장이 들어왔을때 첫번째 단어 y1이 나올 확률이다.
p(y2|y1,x)는 입력문장과 첫번째 단어 y1이 들어왔을때 두번째 단어 y2가 나올 확률이다.
그래서 최종적으로 p(y|x)는 위 식에서와 같이 모든 확률들을 곱했을때의 결과가 된다.
그래서 가장 높은 확률을 얻을 수 있는 경우를 찾으면 된다.
그래서 모든 가능한 경우의 수에 대해서 확률을 계산 할 수도 있지만,
사전에 단어가 V개라면 자릿수가 t개니까, V^t만큼의 경우의 수가 발생한다.
이는 너무 많은 컴퓨팅 자원을 소모하므로 실질적으로 이 모든 경우의 수를 계산 할 수 없다.
# beam search
위에서의 방법은 실현이 불가능하기 때문에 차선책으로 나온 방법이다.
그리디 디코딩과 모든 경우의 수를 찾는 이그조티브 서치 사이의 방법이다.
핵심 아이디어는 디코더의 매 타임 스텝마다, 정해놓은 k개의 가지수를 고려하고,
계산을 해나가면서 가장 마지막에 k개의 가지수 중에 가장 확률이 높은 것을 선택하는 것이다.
k개의 경우의 수에 해당하는 디코딩의 아웃풋을 hyphthesis라고 부르고,
k는 beam size라고 부른다. 이 값은 일반적으로 5에서 10의 값을 가진다.

로그 안에 있는 값을 최대화 해야 하는 것인데,
로그를 취하게 되면 더해지는 것으로 식이 변경된다.
결론적으로 빔 서치가 가장 좋은 결과를 보여주는것은 아니지만,
모든 경우의 수를 다 따지는것보다는 효율적이다.

만약에 k가 2라면 위에 처럼 두가지 경우의 수를 고려하게 된다.

k개의 단어에서 일시적으로 k개의 다음단어를 또 고려하게 된다.

그 다음단계에서 hit과 was가 최종적으로 가장 높은 확률을 가지기 때문에,
그 hit과 was다음에 나올 단어를 고르게 된다.

계속 반복하게 되면 결과를 얻을 수 있다.
그리디 디코딩에서는 모델이 end 토큰을 만들었을때 종료하게 되는데,
빔서치 디코딩에서는 서로 다른 가설로 진행되기 때문에,
다른 시점에서 end 토큰이 발생 할 수 있다.
그래서 어떤 시점에 end 토큰이 발생하면 그 가설은 거기서 종료하고 임시 저장해둔다.
그래서 빔서치의 디코딩은 그 임시 저장된 가설갯수가 일정 갯수를 넘거나,
일정 타임 스텝까지 진행한 경우 종료하게 할 수 있다.
그렇게 얻은 임시 저장된 가설 리스트 중에서 가장 높은 점수를 가지는 하나를 뽑아야 한다.
그런데 각각의 가설들은 길이가 다를수 있는데, 더 긴 가설은 당연히 더 많은 확률을 곱하게 되므로,
(물론 로그를 취했기 때문에 그냥 빼는식으로 되겠지만,)
최종적으로는 더 낮은 확률을 가지게 된다.
그래서 각각의 가설에 대한 확률에, 가설의 길이로 나눠줘서, 워드당 평균 확률을 얻고,
거기서 최대 확률값을 가지는 가설을 선택할 수 있다.
# precision, recall, f-score
자연어 생성모델에서의 생성품질, 그 정확도를 평가하는 척도이다.
만약에 어떤 자리에 어떤 단어가 나와야 한다고 하는 식으로 평가를 진행한다면,
다음과 같은 경우에는 한자리씩 밀리면서 평가점수가 빵점이 될 것이다.
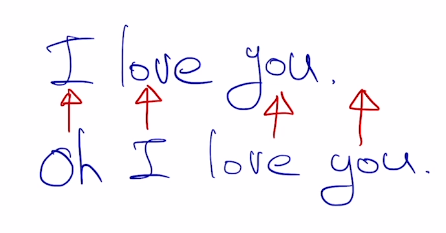
그래서 전체적으로 이게 맞는지 틀린지에 대한 평가 방법을 생각해야 하는데,
프리시전과 리콜이다.

프리시전은 예측한 문장에서 실제로 몇개나 맞았는지 계산하는 것이다.
위에서는 9개의 단어를 뱉었는데 그중에 7개가 맞았으므로 7/9가 된다.
리콜은 나와야 되는 답중에 몇개나 실제로 나왔는지를 계산하는 것이다.
위에서는 10개의 단어가 답으로 나왔어야 했는데, 실제로 답으로 나온것은 7개이므로 7/10이 된다.

그리고 프리시전과 리콜을 조화평균한게 f-measure이 된다.
조화평균을 하는 이유는 일반적으로 산술, 기하, 조화평균중에
조화평균이 더 낮은 값에 가중치를 주기 때문이다.

그래서 모델 두개 결과가 위에 같이 나왔다면,
프리시전, 리콜, f-measure를 구하게 되면 위에처럼 구할 수 있게 된다.
문제는 어순을 고려하지 않기 때문에 모델2에서처럼 어순 구분 없이 막나와서 답이되더라도
높은 점수를 가지게 된다는 것이다.
그래서 BLEU score를 사용하게 된다.
# BLEU score
얼마나 답이 잘 나왔느냐 뿐만 아니라,
연속된 답도 얼마나 잘 나왔는지 따져보는 것이다.
리콜은 무시하게 되는데,
만약 I love this move very much라는 문장을,
나는 이 영화를 정말 많이 사랑한다라는 문장으로 변환해야 했다면,
나는 이 영화를 많이 사랑한다라는 문장으로 실제 변환했더라도 어느정도 맞다고 생각할 수 있다.
그런데 궂이 여기서 리콜을 고려하면 평가에 썩 좋은 영향을 준다고 생각하기는 어려워지기 때문이다.

n그램 갯수만큼의 프리시전을 계산한 다음에는 그 프리시전들을 모두 기하평균해주는데,
이는 보다 적은 프리시전에 가중치를 주기 위함이다.
조화평균을 쓰지 않은 이유는 너무 작은 값이 가중치를 주기 때문이다.

그리고 앞의 min 부분에서는 다음과 같은 일을한다.
만약에 10단어를 생성해야 되는데 7단어만 생성했다면,
분수의 값이 0.7이 될 것이다.
만약에 10단어를 생성해야 되는데 13단어를 생성했다면,
분수의 값이 1.3이 될 것이지만, min에 의해서 1로 조정된다.
이 부분은 두가지 역할을 하는데,
너무 짧은 길이의 문장을 뱉는 경우 뒤에 붙을 프리시전에 페널티를 주겠다는 것이고,
다른 하나는, 리콜의 최대값을 1로 제한해주겠다는 것이다.
그래서 사실상 BLEU는 리콜을 아예 고려하지 않은 것은 아니다.

위에서의 예를 기준으로 실제 BLEU를 구해보면 위와 같다.
BLEU는 0~1사이의 값을 가질수밖에 없다는것을 참고하자.
'ai tech' 카테고리의 다른 글
| ai tech 21회차 (0) | 2021.02.22 |
|---|---|
| ai tech 20일차 (0) | 2021.02.19 |
| ai tech 17일차 (0) | 2021.02.16 |
| ai tech 16일차 (0) | 2021.02.15 |
| ai tech 15일차 (0) | 2021.02.05 |