# self-supervised pre-training models
GPT-1
BERT
# pre-training model의 최근동향
트랜스포머 모델과 셀프 어텐션 블록은 범용적인 시퀀스 인코더 디코더로서 좋은 성능을 보여주고 있다.
트랜스포머는 셀프어텐션블록을 6개정도 쌓아서 사용했다면,
최근에는 더 깊게 쌓아서 만들고 대규모 데이터로 학습하고 transfer learning으로 fine tuning을 해서
더 좋은 성능을 보여주고 있다.
하지만 한글자 다음에 다음 한글자를 추론하는 그리디 디코딩을 벗어나지 못하는 한계점이 있다.
# GPT-1
일론머스크가 세운 openAI에서 나온 모델
자연어 생성에서의 놀라운 성능을 보여준다.

텍스트 시퀀스에 포지션 임베딩을 더하고, 셀프 어텐션 블록을 총 12개를 쌓은 방식이다.
마지막에는 text prediction, task classifier의 작업이 이뤄진다.
# BERT
가장 널리 쓰이는 pre training model이다.
기존에는 전후 문맥을 보지 않고, 앞쪽의 문맥만 본다는 문제가 있었다.
일부 단어를 마스크로 처리해서 그 단어를 맞추는 식으로 학습이 이루어진다.
일부 단어는 k는 15%정도이다.
# next sentence prediction

연속하는 문장을 두고 학습을 시키고,
연속하지 않은 두 문장을 두고 연속하지 않는 문장이라고 학습시킨다.
# BERT summary
1. 셀프 어텐션의 구조를 그대로 사용했다.
두가지 버전인데, 베이스는 셀프어텐션 블록이 12개, 인코딩벡터차원768개, 어텐션헤드가 12개,
라지는 셀프어텐션 블록이 24개, 인코딩벡터차원1024개, 어텐션헤드가 16개이다.
2. 워드를 좀더 잘게 쪼개서 사용한다.
서브워드 단위로 임베딩을 한다.
포지셔널 임베딩도 학습을 통해 진행된다.
분류를 위한 CLS 토큰과 문장 구분을 위한 SEP 토큰이 추가되었다.
세그먼트 임베딩을 진행한다.

세그먼트 임베딩은 몇번째 문장인지 구분하는 것이다.
# fine tuning process
1. sentence pair

sentence pair에 대해서 분류하는 경우
즉, 논리적으로 모순되는 문장인지등을 체크하는 경우
문장 사이에 SEP 토큰을 넣어서 학습을 진행하고,
최종적으로는 CLS 토큰을 넣어서 결과를 얻는다.
2. single sentence

문장앞에 CLS 토큰을 넣고 각각의 한 문장들을 학습시킨후에 CLS 토큰을 넣어서 분류 결과를 넣는다.
3. question answering task

4. single sentence tagging task

각각의 단어에 대해 품사등을 얻어야 하는 경우
CLS로 시작해서 각각 단어의 품사를 얻는다.
# BERT와 GPT-1의 차이점
트레이닝 데이터: GPT는 800M 단어, BERT는 2,500M 단어
특별한 토큰: BERT는 CLS토큰과 SEP토큰, 문장 단위 임베딩(세그먼트 임베딩)을 학습한다.
배치 사이즈: BERT는 128,000단어, GPT는 32,000단어
일반적으로 더 큰 배치 사이즈를 사용하게 되면, 학습도 안정적이고 성능도 좋은 결과를 보인다.
하지만 배치 사이즈를 키우기 위해서는 더 많은 GPU가 필요하다.
변동되는 학습률: GPT는 5e-5의 고정된 학습률을 사용했지만, BERT는 각 태스크 별로 옵티마이징을 진행해야 한다.
# Machine Reading Comprehension
Question Answering의 한 형태이다.
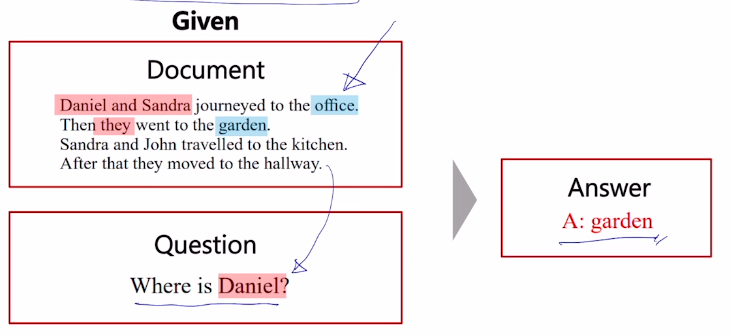
문서가 주어지고 질의 응답이 주어지면 독해기반으로 그 답을 잘 뽑아내는 것이다.
# SQuAD 데이터
위에서의 Question Answering을 위한 데이터이다.
2.0인 경우에는 답이 없는 경우도 포함되어 있다.
일반적으로 학습할때는 질문과 내용, 앞문장과 뒷문장을 합쳐서 학습하고,
CLS 토큰의 결과가 무엇이 나오느냐에 따라 답이 있는지 없는지 알아내고 진행하게 된다.
# GPT-2
트랜스포머의 수가 많고 여전히 다음 단어를 예측하는 방식이다.
좋은 퀄리티의 데이터 40GB로 학습되었다.
언어 모델이 제로 샷 셋팅에서 다운스트림 태스크를 진행할 수 있다는 것을 보여주었다.
자연어 생성을 질의응답에 따라 다르게 나올 수 있다는 것을 보여주었다.
데이터셋은 레딧에서 얻어왔는데 3개이상 추천과 외부링크가 있는 경우 외부링크의 글까지 크롤링해서 사용하였다.
byte pair encoding을 사용하였다.
layer normalization을 사용하였다.
레이어가 위에 갈수록 이니셜라이제이션되는 값이 점점 0에 가까워진다.
# GPT2 question answering
이렇게 얻은 GPT를 사용하여 만든 question answering에서는
질문쿼리를 넣고 바로 답을 유도하는 방식을 사용해보면,
55정도의 f점수가 나오며, fine tuned 된 점수보다는 낮지만 좋은 점수가 나오게 되었다.
# GPT2 summarization
파인튜닝 없이 바로 제로샷을 진행할수도 있는데,
글을 쭉 주고, TL;FR이라는 인자를 주는 것이다.
Too long, didn't read라는 뜻인데,
이 다음에는 요약된 글이 올라왔을 경우가 많았을 것이기 때문에,
GPT2에 TL;FR을 주면 요약된 내용이 생성된다.
# GPT2 traslation
번역하고 싶은 뒤쪽에 wrote in French라고 써주면 다음 문장에 프랑스어가 나오게 된다.
# GPT3
GPT2의 파라미터 숫자를 엄청 늘려준 것이다.
셀프어텐션 모듈을 엄청 많게 만들어주었다.
그리고 더 많은 데이터와 더 많은 배치사이즈를 적용하였더니 더 좋은 성능을 보여주었다.
제로샷 성능이 엄청나게 증가하였다.
물론 원샷, 퓨샷으로 갈수록 성능은 더 좋아진다.
# GPT3의 모델 사이즈

모델 사이즈가 커질수록 성능은 계속 증가하게 된다.
즉, 동적인 적응 능력이 뛰어나다.
# ALBERT
경량화 된 형태의 BERT이다.
점점 더 모델들이 메모리와 성능을 필요로 하는 문제가 있어서,
이를 해결한 모델이다.
# factorized embedding parameterization
셀프디멘션 벡터의 크기는 변하지 않고 유지된다.
알버트는 처음에 입력되는 벡터의 크기는 줄이고,
그 벡터에 공통적으로 내적되는 벡터를 따로 두는 것이다.

# cross-layer parameter sharing
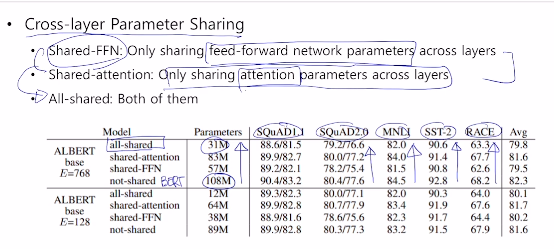
FFN 에서의 파라미터를 공유하게 했을때와,
어텐션에서의 파라미터를 공유하게 했을때의,
파라미터수 차이와 실제 성능 차이이다.
둘 모두 적용하게 되면 성능은 아주 조금 줄어들게 되지만,
파라미터는 거의 3분의 1이하로 감소하였다.
# sentence order prediction
next sentence prediction은 성능향상이 별로 없다고 생각되어서
이를 다른 알고리즘으로 바꾼것이다.
next sentence prediction은 문장 두개를 갖고와서 진행하는것이고,
sentence order prediction은 문장 두개를 갖고와서 앞뒤를 바꿔보면서 진행한다.

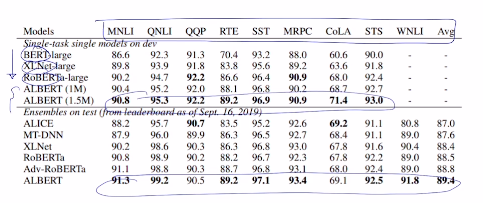
# GLUE Result
# ELECTRA: Efficiently Learning as Encoder that Classifies Token Replacements Accurately

bert를 통과한 단어는 masked 된 내용이 복원되는데
discriminator역할을 하는 electra가 내용이 바뀐건지 학습한다.

같은 학습량이어도 성능이 더 좋은것을 보여준다.
# 경량화 모델
DistillBERT
TinyBERT
ERNIE : 외부 지식베이스를 연결하기
KagNET
'ai tech' 카테고리의 다른 글
| ai tech 25일차 (0) | 2021.02.26 |
|---|---|
| ai tech 21회차 (0) | 2021.02.22 |
| ai tech 18일차 (0) | 2021.02.17 |
| ai tech 17일차 (0) | 2021.02.16 |
| ai tech 16일차 (0) | 2021.02.15 |