# RNN
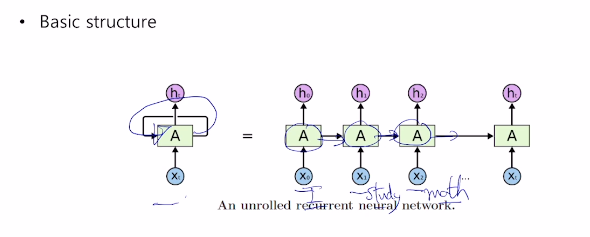
RNN은 시퀀스데이터가 입력 또는 출력으로 주어진 상황에서
각 time step에서 들어오는 입력벡터 xt와 그 전 time step의 RNN 모듈에서 계산한 hidden state 벡터 ht-1를 받아서,
현재 hidden state 벡터 ht를 만드는 구조를 가지고 있다.
예를 들면, I study math라는 문장이 주어졌을때,
각 단어가 time step의 입력으로 들어가게 된다.
매 time step마다 동일한 RNN 모듈 A가 재귀적으로 호출된다.
왼쪽 그림을 rolled version이라고 하고 오른쪽 그림을 unrolled version이라고 한다.

어느 순간에 값을 얻기 위해서는 hidden state로부터 값을 얻어낼 수 있어야 한다.

time step t-1에서의 hidden state 벡터 ht-1
time step t에서의 입력벡터 xt
time step t에서 계산된 hidden state 벡터 ht
w를 파라미터로 가지는 fw 함수
time step t에서의 hidden state ht를 기반으로 계산된 yt
yt는 매 time step에만 계산하는 경우도 있고, 마지막 경우에만 계산하는 경우도 있다.
예를 들어 문장을 입력으로 받아 단어마다 품사를 알아야 하는 경우,
각 단어를 입력으로 받는 time step마다 품사를 출력해야 할수 있다.
또는 문장을 입력으로 받아 긍정인지 부정인지 알아야 하는 경우,
마지막 단어를 읽은후 마지막 time step에서만 긍정부정 여부를 출력한다.
RNN의 가장 중요한 특징은 매 time step마다 사용하는 w가 공유된다는 것이 특징이다.

구체적으로 fw를 정의하면 다음과 같다.
xt가 3차원벡터(임베딩벡터)이고 ht-1이 2차원 벡터라고 하자.
hidden state의 노드수, 차원은 하이퍼 파라미터이다.

Wxh는 입력벡터와 결합하여 Ht를 구하는데 사용되고,
Whh는 이전 히든벡터와 결합하여 Ht를 구하는데 사용된다.

그리고 그 값은 합쳐진 이후 탄젠트 하이퍼볼릭 함수를 거치며 최종적인 Ht가 된다.
그리고 출력벡터가 필요하다면 Wht를 거쳐서 출력벡터를 얻게된다.
가령, 바이너리 분류일때는 스칼라값을 갖게되고 시그모이드 함수를 적용해서 확률 값을 얻는다.
멀티 분류일때는 카테고리만큼의 차원을 갖게되고 소프트맥스 함수를 적용해서 확률 분포를 얻는다.
# Types of RNNs
# one to one

키, 몸무게, 나이로 된 3차원벡터로 된 데이터를 받아서,
2차원벡터로 된 히든 스테이트 벡터로 변환하고,
최종적으로 저혈압인지 정상혈압인지 고혈압인지 분류하는 경우에는 3차원 벡터를 출력으로 내뱉게된다.
# one to many

입력으로 하나의 이미지를 주고,
이미지의 설명글을 각 타임 step별로 출력을 뱉는다.
다만 각 히든 스테이트 계산과정에서 입력이 계속 필요하므로 이런 경우에는 0으로된 벡터를 입력으로 준다.
# many to one

입력문장이 주어지면, 각각의 단어를 워드 임베딩 형태로 time step마다 입력으로 넣고,
마지막의 ht를 사용해서 최종적인 출력 긍정, 부정 여부를 얻는 것이다.
만약에 입력문장의 단어 길이가 다른 경우에는 길이가 달라진 만큼 rnn cell의 크기가 더 길어지게 된다.
# many to many

이 경우는 기계번역이 대표적인 예인데,
어떤 순서로 된 문장을 받아서 다른 언어로 된 문장을 순차적으로 내뱉는 것이다.
마지막 단어를 입력받을 때 부터 출력을 시작한다.

아니면 딜레이가 없이 처음 입력부터 출력을 내뱉을수도 있다.
품사태깅이나 동영상 프레임 분석이 여기에 해당한다.
입력순서를 각각의 동영상 프레임을 받아서 각 프레임에서의 상황을 출력하는 것이다.
# character level language model
언어모델은 시퀀스를 보고 다음에 등장할 것을 예측하는 모델을 말한다.
이것은 단어단위로도 가능하고 문자단위로도 가능하다.
hello를 예를 들면 이것으로 사전 helo를 만들수 있고,
4개의 차원을 갖는 원핫벡터로 변환할 수 있다.



h1을 계산할때는 h0가 필요한데, 이 경우에는 그냥 0 으로 채워진 벡터를 제공한다.
ht를 계산하는 최종단계에는 탄젠트 하이퍼볼릭 함수를 적용한다.

softmax를 적용하면 마지막인 o가 결정될텐데,
이것은 틀렸으므로 back propagation에 의해 가중치가 수정된다.

최종적으로는 이런 모습이 된다.

이런식으로 출력을 바로 다음 입력으로 사용할 수도 있는데,
주식같은 경우는 이런 방식으로 이전날의 데이터를 다음날에 넣어줘서 모델을 지속적으로 학습시키게 된다.

문장을 학습시킬때 공백이나 특수문자, 개행문자를 사전에 포함시키면 이런것들도 학습하게 된다.

학습이 진행될수록 결과가 잘 나오는 것을 볼 수 있다.
# Backpropagation through time(BPTT)

모든 입력에 대해서 손실함수를 모두 계산해서 역전파하려면 너무 많은 리소스가 필요해서
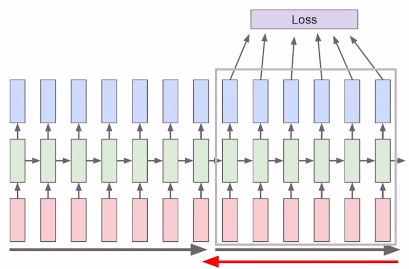
특정 길이만큼의 손실함수를 계산해서 역전파하는 방법을 사용한다.
# searching for interpretable cells

그럼 hidden state 벡터는 실질적으로 어떤 정보를 갖고 있을까?

위와 같이 따옴표 안에 있는 경우에는 가중치가 낮다가 따옴표를 나오게 되면 가중치가 높아지는 등
특정한 정보를 갖고 있는 것을 알 수 있다.

if 문 안에 있는 내용의 경우 가중치가 높고 그 위의 경우에는 작은 것을 알 수 있다.
# Vanishing exploding gradient problem in RNN

오리지널 rnn은 치명적인 문제가 있는데,
time step이 진행될수록 Whh가 계속적으로 곱해지기 때문에,
히든 스테이트가 기하급수적으로 증가하거나 감소하게 된다.
문제는 역전파시에 전달되는 그래디언트가 이전대에 학습될때 너무 적거나 영향력이 없어지게된다.
그래서 LSTM같은것이 일반적으로 사용되는 것이다.
# Long short-term memory
RNN에서 발생하는 gradient vanishig 및 explosion을 해결하고
time step이 먼 경우에도 보다 효율적으로 학습하는 모델이다.
즉, 오리지널 RNN에서의 long term dependency 문제를 해결한 모델이다.

히든스테이트는 어떻게 보면 단기기억으로 볼 수 있는데,
이것을 길게 기억 할 수 있도록 개선한 모델인 것이다.
기본적으로 RNN에서의 히든스테이트를 계산할 때는 다음과 같이 계산한다.

하지만 LSTM에서는 이전단계에서 두가지 서로 다른 기능을 하는 벡터가 들어오게 된다.
기존의 ht와 새로운 ct가 들어온다.

그리고 그것으로 현재 단계의 ct, ht를 구한다.
ct는 주로 셀스테이트 벡터라고 부른다.
ct가 보다 더 완전한 정보를 가지고 있다.
ht는 ct에서 필터링된 정보라고 생각하면된다.

실질적인 계산과정은 다음과 같다.

h를 4개 계산해야되고 x와 h를 concat하면 2h가 되므로
w는 4h*2h가 된다.

그러면 i f o g는 각각 무엇을 의미할까

우선 forget 게이트에서는 이전 히든 스테이트에 forget 벡터를 시그모이드 연산을 해서
이전 time step에서 넘어온 정보중에 특정 비율만을 보전해주게 된다.

그리고 나서 현재 단계의 Ct를 만들게 된다.

그 이후에 현재 단계의 Ht를 만든다.

Ht는 그 단계에서의 필요한 정보를 주로 담고 있기 때문에 출력쪽에서 사용하도록 보내주게 된다.
만약에 따옴표가 열고 닫는문장을 생각한다면,
따옴표가 열려있다는 정보는 Ct에 저장해두고,
지금 당장 어떤 정보가 나와야 한다는 것은 Ht에 저장해 두는 것이다.
# Gated Recurrenct Unit(GRU)

GRU는 Ht에 Ct를 합쳐놓았다고 생각하면된다.
그리고 독립된 게이트가 수행하던 역할을 하나의 게이트가 하도록 한 것이다.
그래서 계산량과 메모리 요구량을 줄이게 된다.
이렇게 경량화되었지만 좋은 성능을 보여준다.
그리고 계속적으로 같은 w를 내적해주는것이 아니므로 long term dependency 문제도 해결 된다.
'ai tech' 카테고리의 다른 글
| ai tech 20일차 (0) | 2021.02.19 |
|---|---|
| ai tech 18일차 (0) | 2021.02.17 |
| ai tech 16일차 (0) | 2021.02.15 |
| ai tech 15일차 (0) | 2021.02.05 |
| ai tech 14일차 (0) | 2021.02.04 |