# NLP
Tokenization: 주어진 문장을 단어단위로 쪼개나가는것, 결과적으로 시퀀스가 된다.
stemming: 수많은 어미 변화에도 같은단어라는것을 컴퓨터가 알아야하므로 어근만 추출해 내는것이다.
NER: 단일단어나 여러단어로 된 고유명사를 인식해내는것이다.
part-of-speech tagging: 주어인지 목적어인지 등을 찾아내는 것이다.
sentiment analysis: 문장이 긍정인지 부정인지 알아내는 것이다.
machine translation: 번역
entailment prediction: 문장간의 사실관계와 모순관계를 찾아내는 것이다.
question answering: 질문을 이해하고 정답을 보여주는것이다.
dialog system: 챗봇
summarization: 뉴스 한줄 요약 등
# NLP major conferences
ACL, EMNLP, NAACL
# text mining
빅데이터에서 단어의 빈도수 등을 기반으로 정보를 얻어냄
토픽모델링을 이용하여 문서 군집화 등을 할 수 있음
# text mining conferences
KDD, The WebConf(WWW), WSDM, COKM, ICWSM
# Information retrieval
추천 시스템
# Information retreival major conferences
SIGIR, WSDM, CIKM, RecSys
# trends of nlp
텍스트 데이터를 단어단위로 변환하고 이를 벡터공간의 한 점으로 나타낸다.(워드 임베딩)
단어단위로 변환하더라도 순서에 따라서 의미가 달라지기 때문에 시퀀스 데이터로서 의미를 가져야 하고,
그래서 텍스트마이닝 분야에서는 RNN-family models이 사용된다.
그러다가 attention is all you need 라는 논문이 구글에서 발표되면서 transformer models로 패러다임이 전환되었다.
처음에 트랜스포머는 기계번역을 위해서 제안되었다.
그러나 이제는 다른 분야에서도 성능 향상을 위해서 사용되고 있다.
self attention 모듈을 단순히 쌓아나가는 식으로 모델 크기를 키우고
이 모델을 대규모 텍스트 데이터를 통해 자가지도학습을 하고,
사전된 학습된 모델을 원하는 태스크의 전이학습의 형태로 적용한다.
이렇게 적용하면 그 태스크만을 위해 특화된 학습을 진행한 모델보다도 월등한 결과를 보여준다.
사전학습, pre trained 모델의 예시로서 bert, gpt-3 등의 모델이 있으며,
특정한 task만 진행하는 모델에서 발전해서 범용인공지능학습으로 나아갔다고 볼 수 있다.
하지만 pretrained 모델을 구현하기 위해서는 많은 gpu 성능이 필요하다.
# bag of words
1단계: 문장으로부터 vocabulary를 만든다.
"John really really loves this movie"
"Jane really likes this song"
John, really, loves, this, movie, Jane, likes, song
2단계: vocabulary를 one hot vector로 만든다.
| John | 1 0 0 0 0 0 0 0 |
| really | 0 1 0 0 0 0 0 0 |
| loves | 0 0 1 0 0 0 0 0 |
| this | 0 0 0 1 0 0 0 0 |
| movie | 0 0 0 0 1 0 0 0 |
| Jane | 0 0 0 0 0 1 0 0 |
| likes | 0 0 0 0 0 0 1 0 |
| song | 0 0 0 0 0 0 0 1 |
이렇게 만들면 두 벡터간의 거리는 무조건 루트(2)가 된다.
그리고 두 벡터간의 코사인 유사도는 0이 된다.
# bag of words vector
단어들의 벡터를 합쳐서 문장을 표현할 수도 있다.
| John really really loves this move | 1 2 1 1 1 0 0 0 |
| Jane really likes this song | 0 1 0 1 0 1 1 1 |
# naive bayes classifier



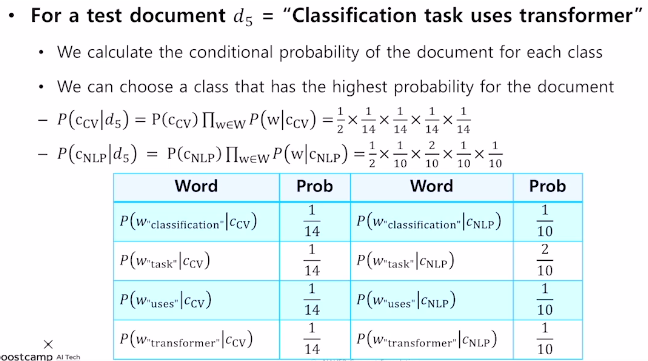
어떤 문서가 어떤 카테고리일 확률을 구할때,
어떤 카테고리가 전체 문서에서 나올 확률 * 어떤 카테고리에서 단어들이 등장할 확률을 구해주는 것이다.
다만, 새로운 단어가 나타난다면 단어가 등장할 확률이 0이되는 문제가 있다.
그래서 다양한 regularization 기법들이 필요하다.
# word embedding
단어들을 각각의 시퀀스로 볼 때에,
각 단어들을 특정한 차원으로 이뤄진 공간의 한 점, 벡터로 변환해주는 기법이다.
비슷한 의미의 단어가 좌표공간의 비슷한 위치에 있도록해서 단어들의 의미상 유사도를 잘표현한다.
감정분석태스크를 진행할때 love와 like가 비슷한 위치에 있기 때문에 둘 모두를 긍정으로 분류 할 수 있다.
# word2vec
어떤 한 단어가 주변에 등장하는 단어를 통해 그 의미를 알 수 있다.
한 문장 내에서 인접한 단어간의 의미가 비슷할 것이라는 가정으로 진행된다.
the cat purrs
this cat hunts mice
두 문장을 살펴보면 the와 this는 cat을 꾸며주는 어떤 단어라는 것을 알 수 있고,
purrs와 hunts는 cat이 주로 하는 행동이라는 것을 알 수 있다.
mice는 hunts라는 행동을 할때 그 대상이 된다.
주어진 학습데이터를 바탕으로 cat주변에 나타나는 단어들의 확률 분포를 예측하게 된다.
구체적으로는 cat단어만 가지고 주변 단어를 숨긴 후에 예측하는식으로 학습이 진행된다.
# 구체적인 word2vec 알고리즘

문장이 I study math일때,
사전은 I, study, math 세개의 단어로 구축하고 원핫벡터로 나타낸다.
sliding window를 구성하고 중심단어와 주변단어 각각의 쌍으로 구성한다.
그리고 하나의 히든레이어를 가지는 네트워크를 만드는데,
입력 레이어와 출력레이어의 노드 수는 단어의 크기인 3이된다.
히든 레이어의 노드 수는 사용자가 정하는 하이퍼 파라미터이다.
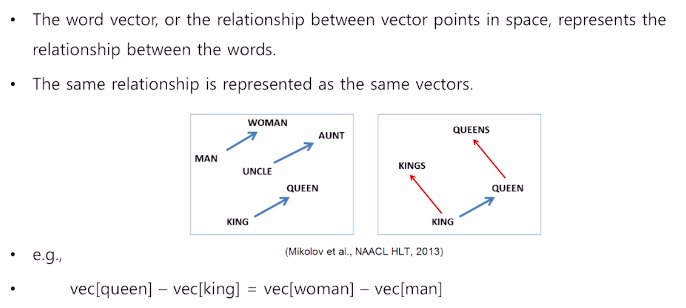
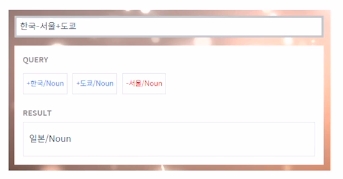
이렇게 학습된 벡터는 서로 연산도 가능하다.
# glove

입력, 출력 쌍에대해서 학습데이터에서 두 단어가 한 윈도우 내에서 몇번 동시에 등장했는지를 사전에 계산을 하고,
내적값에서 두 단어가 동시에 등장할 확률에 로그값을 취해준것을 빼주는 형태로 손실함수를 새로 정의한 것이다.
중복되는 연산을 줄여준다는 점에서 학습이 더 빠르게 진행될 수 있다.
'ai tech' 카테고리의 다른 글
| ai tech 18일차 (0) | 2021.02.17 |
|---|---|
| ai tech 17일차 (0) | 2021.02.16 |
| ai tech 15일차 (0) | 2021.02.05 |
| ai tech 14일차 (0) | 2021.02.04 |
| ai tech 13일차 (0) | 2021.02.03 |