# convolution

신호처리 분야에서 두개의 함수가 있을때 두 함수를 잘 섞어주는 방법 또는 연산자이다.
연속적인 형태와 이산적인 형태로 나눠서 볼 수 있다.

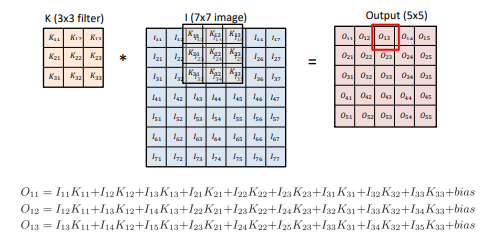
I라는 것이 전체 이미지라고 하면 K를 필터라고 볼 수 있다.

3*3 필터에 7*7 이미지를 컨볼루션하면 5*5출력이 나오게 된다.

소위 도장을 찍는다고 표현할 수 있는데 필터 행렬을 이미지 행렬에 순차적으로 찍어서
행렬곱을 하고 출력 행렬의 원소를 얻는 것이다.

# 그럼 convolution을 어디다 써먹을까?
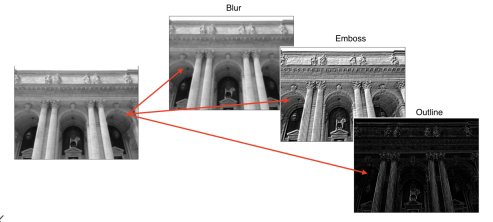
이미지에 필터를 컨볼루션하게되면 이미지를 블러하거나 엠보스하거나 외곽선만 따는 등의
기능을 할 수 있게 된다.
# RGB 이미지

32 * 32 이미지라고 하면 3개의 채널이 있다.
5 * 5 필터로 컨볼루션하더라도 필터에 3개의 채널이 필요하다.
즉, 이미지의 채널 갯수와 필터의 채널 갯수는 같아야 한다.
이때 필터가 하나이므로 출력의 채널 갯수는 1이 된다.
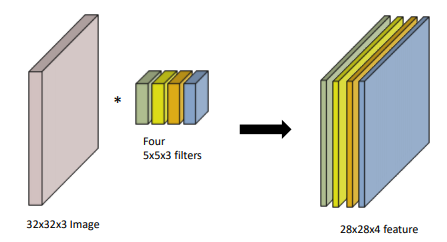
결론적으로 출력에 만약에 채널이 여러개 있다면 필터가 그 갯수만큼 걸렸다는 것을 의미한다.
다시 말하면 입력채널갯수와 출력채널갯수를 알면 필터의 갯수도 알 수 있다.

위에서처럼 그림만 봐도 어떤 필터가 적용되었는지 알수 있게 되는데,
32 * 32 * 3 이미지가 필터를 거치고 28 * 28 * 4가 되었으므로,
4개의 5 * 5 * 3 의 필터가 사용되었다는것을 유추할 수 있고,
28 * 28 * 4 이미지가 필터를 거치고 24 * 24* 10이 되었으므로,
10개의 5 * 5 * 4 의 필터가 사용되었다는것을 유추할 수 있다.
# 일반적인 CNN 구조

이미지를 도장처럼 찍어서, 즉 필터를 한 convolution layer가 있고,
여기서 pooling layer를 얻게 된다.
이부분의 설명은 없지만, pooling layer를 만드는 방법은
2*2 pooling, average pooling, max pooling 등이 있다.
마지막에 이 내용들을 모두 합쳐서, 최종적으로 원하는 결과값을 만들어주는,
fully connected layer가 된다.
즉, convolution 과 pooling 레이어가 해주는건 feature extraction,
이미지에서 정보를 뽑아주는것이되고,
fully connected layer는 분류나 회귀를 해서 원하는 출력값을 얻는 부분이 된다.
이렇게 만들어지는게 일반적이고 고전적인 CNN이고,
최근들어서는 fully connected layer가 없어지거나 축소되고 있다.
파라미터 숫자에 의존성이 있는데,
학습시키고자 하는 모델의 파라미터의 숫자가 늘어날수록
학습이 어렵고 generalization performace가 떨어지는것으로 알려져 있다.
학습에서의 결과가 테스트데이터에서 잘 동작하지 않는다는것이다.
그래서 CNN의 발전은 convolution 레이어는 깊게 가져가지만,
파라미터 숫자는 줄이는 방향으로 진행된다.
그래서 네트워크 파라미터가 몇개로 이루어져 있고,
전체 파라미터의 숫자가 몇개인지 감을 잡고 있어야 하는게 필요하다.
# google net의 파라미터갯수예시

# stride

넓게 걷는다는것을 말한다.
여태까지는 stride가 모두 1이어서 한칸씩만 이동했었다.
stride가 2인경우에는 두칸씩 이동하게 된다.
2d니까 stride가 한개인거지 3d가 되면 stride는 두 축 방향으로 각각 두개가 있게 된다.
# padding

바운더리쪽에는 필터를 찍지않기 때문에 어떤 값을 넣어놓고 필터를 찍는것을 말한다.
제로패딩이라하면 그 값이 0으로 들어가게된다.
패딩을 하고 필터를 사용하면 입력과 출력의 크기가 같게 된다.
# stride & padding

위에서는 필터크기가 3*3밖에 안되니깐
입력과 같은 크기의 출력을 얻으려면 패딩이 1만 필요한데,
만약에 필터크기가 5*5였다면 패딩이 2가 필요했을 것이고,
필터크기가 7*7이었다면 패딩이 3이 필요했을 것이다.
결론적으로 적절한 크기의 padding을 하고 stride가 1이되면 같은 크기의 결과가 나온다.
# 파라미터 숫자 계산하기

w와 h가 크기이고, 채널이 128개이다.
출력도 크기가 같고, 채널은 64개이다.
64개의 채널이 결과가 있으니깐 64개의 필터가 적용된것이고,
필터의 채널은 입력의 채널과 같아야 하니까 채널은 128이된다.
필터 크기는 3*3으로 주어졌으므로,
결론적으로는 3 * 3 * 128 * 64가 되는 것이다.
그래서 파라미터의 숫자는 이를 계산한 것이고,
파라미터의 숫자는 padding과 stride는 파라미터 숫자와는 무관하다는 것을 기억하자.
뒤에서 다른 네트워크 모양만 봐도 감이 생겨야 할 정도로 알아야 한다.
# alexnet 예시

처음에 들어오는 이미지가 224*224라는것을 알수 있다.
채널은 3개이다.
여기에 11*11 컨볼루션이 일어난다.
그럼 각각의 커널은 11 * 11 * 3 이라는것을 유추할수 있고,
출력이 48개 이므로 커널은 48개가 적용된 것이다.
그리고 이 과정을 서로 다른 네트워크로 지나가도록 두번 진행한 것이다.


5 * 5 * 48 * 128 * 2 같은방식으로 구해진다.

3 * 3 * (128 * 2) * (192 * 2)



fully connected layer의 차원은 입력의 파라미터 갯수와 출력 파라미터 갯수를 곱한것은 같다.
입력값 13 * 13 * 128 * 2 * 출력값 2048 * 2

convolution 레이어를 지날때도 파라미터 갯수가 늘기는 하지만,
fully connected layer를 지날때 파라미터의 갯수가 거의 1000배가 증가하는것을 알 수 있다.
대부분의 파라미터가 fully connected layer에 들어가기 때문에, 이렇게 증가하는 것이다.
# 1*1 convolution

필터크기가 1이되면 무슨의미가 있을까 싶지만, 채널을 확줄여버릴수 있다.
즉, convolution layer을 더 깊게 쌓으면서 파라미터 숫자는 획기적으로 줄일수 있게 된다.
# ILSVRC(ImageNetLarge-ScaleVisualRecognitionChallenge)
Classification/Detection/Localization/Segmentation
1000여개의 다른 카테고리들이 있다.
100만장이 넘는 이미지
트레이닝셋은 45만개이상으로 점점 늘어나고 있다.

연도별 틀리는 성능인데, 2015년부터는 사람보다 성능이 좋아졌다.
# alexnet

네트워크가 두개로 나눠져있는데, 두장의 gpu에 따로 학습하기 위해서 그렇게 만든 것이다.
11 * 11 필터를 사용했는데 그렇게 좋은것은 아니다.
총 9개의 레이어로 되어있는 뉴럴네트워크이다.
ReLU를 사용했고 효과적이었다.
GPU를 2개 사용했다.
LRN(Local response normalization)은 신경 안써도되는데, 어떤 입력공간에서 response가 많이 나오면 몇개를 죽이는 것이다.
최종적으로 원하는건 sparce한 activation을 원하는 것이다. 그러나 요즘 활용되지는 않는다.
overlapping pooling 사용
data augnetation 사용
dropout(뉴런 중에서 몇개를 0으로 바꾸는것) 사용
위 내용들은 현재는 일반적으로 쓰이는 내용들이지만, 이 당시에는 당연한게 아니었고,
위 내용들이 일반적인 좋은 성능으로 주로 쓰이게 되는 시작이된다.
# ReLU

0보다 작은값에 대해서는 0으로 바꾼다.
리니어 모델의 좋은 성질들을 그대로 갖고있다.
그래디언트가 액티베이션보다 커도 그대로 갖고있게 된다. 0 보다 작을때는 0으로 바꿔주고
학습에 용이하고, 결과론적으로는 좋은 generalization 성능을 갖는다.
시그모이드나 하이퍼볼릭 탄젠트 함수가 0에서 멀어지면 그래디언트가 0에 수렴하는 문제가 있는데,
이 함수는 그런게 없다.
# VGGNet

3 * 3 컨볼루션 필터만 사용하였다.
1 * 1 컨볼루션을 사용했지만, 의미는 없는게 파라미터 숫자를 줄이려고 사용한건 아니다.
드랍아웃을 사용했고, 레이어 갯수에 따라 VGG16, VGG19로 나뉜다.
중요한건 3 * 3 컨볼루션을 활용했다는 것이다.
# 왜 3 * 3 컨볼루션인가

3 * 3 필터를 두번 거치면, 사실상 5 * 5 필터를 한 것과 receptive field 상에서는 같은 결과를 갖는다.
하지만 파라미터를 계산해보면 3 * 3 필터를 두번 거치는게 더 파라미터 갯수가 적다.
# google net

중간중간에 1*1 컨볼루션을 잘 활용하면, 파라미터 숫자를 줄일수 있다고 했다.
구글넷은 이것을 활용했다.
네트워크 안에 네트워크가 있는 network in network 구조와 inception block을 잘 활용했다.
# inception block

입력이 들어왔을때 여러개로 퍼졌다가 하나로 합쳐지는 것이다.
중요한 점은 입력에 1*1 컨볼루션을 진행한다는 것이다.
이것은 전체적인 파라미터의 갯수를 줄이게 된다.
채널 방향으로 dimension을 줄이기 때문이다.

3 * 3 컨볼루션을 한다고 했을때, 파라미터의 숫자는 위와 같다.

1 * 1 컨볼루션을 중간에 넣게 되면, 채널방향으로 정보를 확 줄이게된다.
이 결과를 3 * 3 컨볼루션을 진행하면 결과적으로 훨씬 적은 파라미터를 갖게된다.
# 퀴즈

# ResNet
파라미터 숫자가 많게되면 과적합되는 경우가 많다.

물론 위에서는 테스트에러가 갈수록 줄어들기 때문에 과적합인것은 아니지만,
56레이어가 20레이어보다 결과가 더 안좋은것을 보여주고 있다.

그래서 resnet은 identity map이라는 것을 추가한다.
skip connection으로 입력을 레이어의 출력에 더해준다.
결국 학습하기 원하는것은 입력과 그 출력의 차이를 학습하게 하는것이다.

그러면 기존에는 더 많은 레이어가 성능이 안좋게 나왔지만,
이제는 더 많은 레이어가 성능이 더 좋게 나온다.
즉, 학습 자체를 더 잘 할수 있게 된것이다.
원래는 20단을 넘어가면 학습이 잘 안됐지만, 이것을 기점으로 더 레이어가 깊어지면 학습을 잘 할수 있게 되었다.

문제는 더해줄때 차원이 같아야 한다는 것인데,
차원이 같을 때는 그냥 더해주면되는거고,
차원이 다를 때는 1 * 1 컨볼루션을 해서 채널 뎁스를 맞춰준다.

재밌는 점은 배치놈은 컨볼루션 다음에 일어난다는 것이다.
배치놈을 ReLU다음에 넣어야 잘된다는 사람들도 있다.

bottleneck architecture는 구글에서의 inception structure와 같다.
3 * 3 컨볼루션하기 전에 1 * 1 컨볼루션을 해서 인풋 채널 숫자를 줄이고
3 * 3 컨볼루션 이후에 1 * 1 컨볼루션으로 다시 채널을 늘려서 차원을 맞춘다.

갈수록 성능은 높아지면서 파라미터 수는 줄어드는 것을 볼 수 있다.
# DenseNet

ResNet에서는 컨볼루션 결과에 인풋을 더해줬다면, DenseNet은 그냥 concat해주는것이다.

문제는 concat을 하게 되면 채널이 점점 기하급수적으로 커진다는 것이다.
그래서 중간에 한번씩 1 * 1 컨볼루션으로 채널을 줄여줘야 한다.

dense block이라는 것은 concatenates 된 피쳐맵을 말하고,
trasition block이라는 것은 마지막에 배치놈을 하고 1 * 1 컨볼루션으로 채널을 줄여주는것을 말한다.
위 두개를 반복해 가면서 진행된다.
# 결론
VGG: 3 * 3 컨볼루션을 사용하는게 다른 더 큰 컨볼루션을 쓰는것보다 좋고,
GoogLeNet: 1 * 1 컨볼루션을 사용해서 채널의 갯수를 줄여 파라미터 갯수를 줄일 수 있고,
ResNet: skip-connection으로 layer의 depth를 깊게 쌓을수 있고,
DenseNet: skip-connection이 아닌 concatenation으로 해도 좋은 성능을 낼수있었다는 것이다.
# semantic segmentation

이미지의 모든 픽셀이 어디에 속하는지 알고 싶은 것이다.
사진에서 어떤 부분은 배경이고, 어디는 사람이고, 어디는 물체인지 알아내는 것이다.
그래서 dense classification, per pixel classification으로 불리기도 한다.

자율주행이나 운전보조장치에서 이게 잘 사용되는데,
카메라로 앞에 사람이 있는지, 다른 차인지, 인도인지 알아낼 수 있어야 하기 때문이다.
특히 라이다가 없이 구현하려면 이 기술이 매우 중요하다.
# fully convolutional network

일반적인 CNN은 위와 같이 생겼다.
컨볼루션을 진행하다가, 플랫을 해서 한줄로 펴서 하나의 벡터로 만들고,
이 벡터로부터 내가 원하는 차원으로의 fully connected layer를 만들면 이게 CNN이다.

fully convolutional network는 위와 같이 dense layer를 없애고 싶은 것이다.
위 두개는 파라미터 갯수는 정확하게 일치한다.
20 * 20 * 1000짜리를 flat 한다음에 40만짜리 벡터를 얻어서 dense하는게 아니라,
20 * 20 * 1000짜리 필터, 커널을 만드는 것이다.

4 * 4 * 16 을 플랫하면 그냥 256짜리 벡터가 된다.
이것을 10개짜리 출력으로 바꾸면, 256 * 10이므로 2560개가 된다.
오른쪽에서 4 * 4 * 16에 4 * 4 * 16 필터 10개를 컨볼루션을 진행하는것이다.
그래서 4 * 4 * 16 * 10 = 2560이다.
이렇게 fully convolutional network로 바꾸는것을 convolutionalization이라고 한다.
달라지는게 없는데 왜 할까?
인풋이미지의 크기에 종속되지 않기 때문이다.

convolution은 이미지 크기에 상관 없이 동일한 필터가 찍어주기 때문에,
찍어서 나오는 결과만 같이 커지지 동작은 가능하다.
그래서 그 동장이 마치 히트맵과 같은 효과를 얻게 된다.
그래서 더 큰 이미지에서 고양이가 어디 있는지 히트맵으로 위치를 알 수 있게 된다.
원래는 이미지 분류만 됐었는데, 이제 큰 이미지 안에 어떤 이미지가 있는지 알게 된 것이다.
다만 output dimension이 줄어들게 된다.
100 * 100 이었으면 10 * 10이 나오게 된다.
그래서 이것을 다시 100 * 100으로 늘려야 하는 방법이 필요하다.
# deconvolution(conv transpose)

convolution의 역 연산이다.
convolution에서는 stride를 2를 주게 되면, dimension이 반정도 줄게 된다.
deconvolution에서는 stride를 2를 주게 되면, dimension이 두배로 늘게 된다.
그래서 이것을 이용해서 special dimension을 키워 줄 수 있게 된다.
근데 엄밀히는 convolution의 역연산이라는 것은 존재할 수가 없다.
이미 필터로 convolution한 결과값을 다시 이전값으로 돌릴수는 없기 때문이다.
근데 왜 역연산이냐고 하냐면 그냥 역연산이라고 생각하면 차원계산할때 엄청 편해지기 때문이다.

실제로는 deconvolution은 이런 방식이다.
padding을 많이줘서 얻고싶은 5*5 결과를 얻는다.

인풋 이미지가 들어가고
Fully conversion network를 만든 다음에,
부분 분류를 만드는것이 FCN구조가 된다.
# detection
# R-CNN
이미지 안에서의 바운딩 박스를 찾는 것이다.
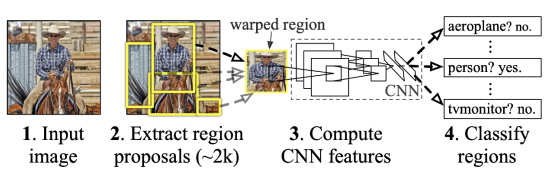
이미지에서 크기가 다른 2000개의 region을 뽑아낸다.
이것을 똑같은 크기로 맞춘다.
그리고 feature는 alex를 이용해서 뽑아낸다.
그리고 이것을 SVM을 이용해서 분류한다.
# SPPNet
R-CNN은 문제가 있는데,
이미지 안에서 2000개의 바운딩박스를 뽑으면,
2000개의 이미지를 CNN에 모두 통과시켜야 한다는 것이다.
그래서 cpu에서는 하나의 이미지만 처리하는데도 1분이 넘게 걸린다.
SPPNet은 이미지 안에서 CNN을 한번만 돌리고자 하는 것이다.
이미지 전체에 covolutional feature map을 만든 다음에,
뽑힌 바운딩 박스 위치에 해당하는 텐서만 들고오자는 것이다.
# Fast R-CNN

하지만 그것도 느릴수밖에 없는데,
Fast R-CNN은 SPPNet에서의 feature map을 만들고 Rol pooling layer를 만드는 것까지는 거의 동일하지만,
그뒤에 바운딩 박스를 어떻게 옮길것인지, 바운딩박스에 대한 라벨을 찾는것은 뉴럴네트워크로 하는 것이다.
# Faster R-CNN
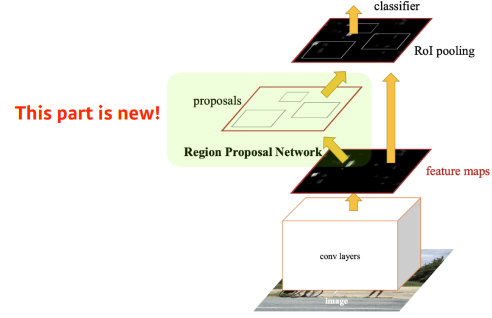
이미지를 통해서 바운딩 박스를 뽑아내는 region proposal이라는 것도 학습을 통해 하자는 것이다.
위에서의 R-CNN 계열 방법들은 그냥 임의의 바운딩박스를 만들어서 진행하는데,
여기서는 바운딩 박스를 만드는 것조차도 학습을 통해 진행한다.
이것을 region proposal network로 진행한다.
# Region Proposal Network(RPN)

이게 해주는건 간단하다.
이미지에서 특정 영역이, 바운딩 박스가 이미지 영역으로서의 의미가 있을지 없을지를 찾아주는 것이다.
이것이 무엇인지는 뒤에서 다른 네트워크가 해주지만, 이 안에 무언가 있다고 인식하는것을 이게 해주는 것이다.
이걸 할때 anchor box라는게 필요한데, 미리 정해놓은 bounding box의 크기이다.
즉, 사진 안에 어떤 크기의 물체가 있을지 알고 있어야 한다.
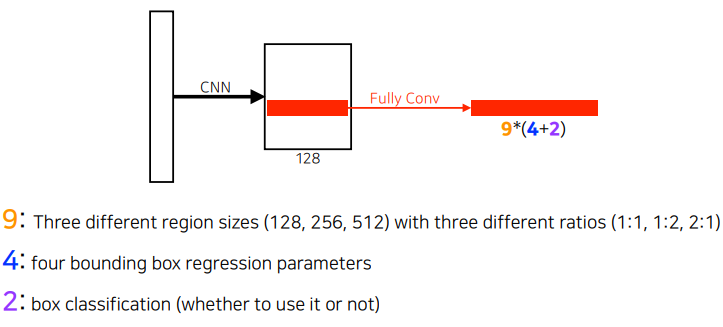
여기서도 fully convolution network가 활용된다.
anchor box의 사이즈는 9개가 미리 정해져 있고,
각각의 바운딩박스마다 크기를 얼마나 키우고 줄일지, width와 height를 정하고 x, y offset을 정하는 형태이기 때문에 4개가 필요하고,
해당 박스가 필요한지 아닌지 2개의 파라미터가 필요하다.

좀더 다양한 물체와 얇고 작은 것도 찾아낼 수 있다.
# YOLO

바운딩 박스를 따로 뽑는 과정이 없기 때문에 빠르다.

이미지를 그리드로 나누게 되고,
내가 찾고 싶은 물체의 중앙이 해당 그리드 안에 들어가게 되면,
그 그리드 셀이 해당 물체에 대한 바운딩 박스와, 그 해당 물체가 무엇인지를 같이 예측한다.

각각의 셀은 특정한 갯수의 바운딩 박스를 예측한다.
그리고 그 바운딩박스가 쓸모있는지 아닌지 같이 예측한다.

동시에 그리드의 각각의 셀이 어떤 클래스인지를 예측하게 된다.

마지막에 둘의 정보를 취합하면 박스와 그 박스가 어느 클래스인지를 알수 있게 되는 것이다.
결론적으로 바운딩박스를 찾아내는것과 클래스를 찾아내는 것을 동시에 하기 때문에 엄청 빠른 것이다.
'ai tech' 카테고리의 다른 글
| ai tech 15일차 (0) | 2021.02.05 |
|---|---|
| ai tech 14일차 (0) | 2021.02.04 |
| ai tech 12일차 (0) | 2021.02.02 |
| ai tech 11일차 (0) | 2021.02.01 |
| ai tech 10일차 (0) | 2021.01.29 |