# pandas
구조화된 데이터의 처리를 지원하는 파이썬 라이브러리
파이썬에서 사용하는 엑셀이라고 생각하면 된다.
panel data라는 단어에서 pandas라는 단어가 나왔다.
numpy와 통합하면서 강력한 스프레드시트 처리 기능 제공
인덱싱, 연산용 함수, 전처리 함수 등을 제공
데이터 처리 및 통계 분석을 위해 사용
테이블 형태(tabular)의 데이터를 처리할 때 사용한다.
# 사용하는 용어

# 설치
conda create -n ml python=3.8 # 가상환경생성
activate ml # 가상환경실행
conda install pandas # pandas 설치
jupyter notebook # 주피터 실행하기# 데이터 로딩
import pandas as pd
data_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data"
df_data = pd.read_csv(data_url, sep="\s+", header = None)
df_data.head() # 처음 5줄 출력
# 구성
Series: DataFrame 중 하나의 Column에 해당하는 데이터의 모음 object
DataFrame: DataTable 전체를 포함하는 object
# Series
기존 데이터가 있고, 기존 데이터에 접근하는 인덱스를 정의할수 있다.
ndarray의 서브클래스이다.
# 기본적인 시리즈 데이터 만들기
list_data = [1, 2, 3, 4, 5]
list_name = ["a", "b", "c", "d", "e"]
example_obj = Series(data=list_data)
example_obj# 아예 사전 형태로 받을 수도 있다.
dict_Data = {"a":1, "b":2, "c":3, "d":4, "e":5}
example_obj = Series(dict_data, dtype=np.float32, name="example_data")
example_obj
# a 1.0
# b 2.0
# c 3.0
# d 4.0
# e 5.0# 데이터 타입 변경하기
example_obj = example_obj.astype(float)
# 접근하기
example_obj["a"]
# 할당하기
example_obj["a"] = 3.2# 데이터에 대한 이름을 설정할 수도 있다.
example_obj.values
example_obj.index
example_obj.name = "number"
example_obj.index.name = "alphabet"
example_obj
# alphabet
# a 3.2
# b 2.0
# c 3.0
# d 4.0
# e 5.0
# Name: number, dtype: float64# 판다스는 인덱스 값을 기준으로 객체를 생성한다.
dict_data_1 = {"a":1, "b":2, "c":3, "d":4, "e":5}
indexes = ["a", "b", "c", "d", "e", "f", "g", "h"]
series_obj_1 = Series(dict_data_1, index=indexes)
series_obj_1
# a 1.0
# b 2.0
# c 3.0
# d 4.0
# e 5.0
# f NaN
# g NaN
# h NaN
# dtype: float64# dataframe
시리즈에 칼럼이 추가된 개념이다.
칼럼마다 데이터 형태가 달라도 된다.
raw_data = {
"first_name": ["Jason", "Molly", "Tina", "Jake", "Amy"],
"last_name": ["Miller", "Jacobson", "Ali", "Milner", "Cooze"],
"age": [42, 52, 36, 24, 73],
"city": ["San Francisco", "Baltimore", "Miami", "Douglas", "Boston"],
}
df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city"])
df
# first_name last_name age city
# 0 Jason Miller 42 San Francisco
# 1 Molly Jacobson 52 Baltimore
# 2 Tina Ali 36 Miami
# 3 Jake Milner 24 Douglas
# 4 Amy Cooze 73 Boston
# 데이터프레임도 인덱스와 칼럼을 기준으로 데이터를 표현한다.
df = pd.DataFrame(raw_data, columns=["first_name", "last_name", "age", "city", "debt"])
df
# first_name last_name age city debt
# 0 Jason Miller 42 San Francisco NaN
# 1 Molly Jacobson 52 Baltimore NaN
# 2 Tina Ali 36 Miami NaN
# 3 Jake Milner 24 Douglas NaN
# 4 Amy Cooze 73 Boston NaN# dataframe에서 series 가져오기
df.first_name
df["first_name"]
# 0 Jason
# 1 Molly
# 2 Tina
# 3 Jake
# 4 Amy
# Name: first_name, dtype: object# 인덱싱
loc을 사용하면 인덱스 이름으로 row를 반환하고,
iloc을 사용하면 인덱스 숫자로 row를 반환한다.
s = pd.Series(np.nan, index=[49,48,47,46,45,1,2,3,4,5])
s.loc[:3] # 인덱스 이름이 3인데까지 불러와라
# 49 NaN
# 48 NaN
# 47 NaN
# 46 NaN
# 45 NaN
# 1 NaN
# 2 NaN
# 3 NaN
# dtype: float64
s.iloc[:3] # 인덱스 숫자 3까지 불러와라
# 49 NaN
# 48 NaN
# 47 NaN
# dtype: float64
df.loc[:, ["last_name"]]
# last_name
# 0 Miller
# 1 Jacobson
# 2 Ali
# 3 Milner
# 4 Cooze# 전치행렬
df.T# csv 변환
df.to_scv()# 열삭제
df.drop("dept", axis=1)# 2중 dict
json 데이터일때 2중 dict 형태이면 바로 dataframe으로 만들 수 있다.
pop = {"Nevada":{2001:2.4, 2002:2.9}, "Ohio":{2000:1.5, 2001:1.7, 2002:3.6}}
DataFrame(pop)# data selection
# 한개의 column을 선택하고 시리즈 형태로 출력
df["account"].head(3)
# 한개이상의 column 선택하고 데이터프레임 형태로 출력
# 즉, 리스트를 하나 더 만들고 안에 column을 넣으면 데이터프레임형태로 출력
df[["account", "street", "state"]].head(3)
# 인덱스 번호 기준으로 출력
df[:3] # 인덱스가 0, 1, 2로 되어있으면 출력된다.
df["account"][:3]
df["account"][[0, 1, 2]]
account_series = df["account"]
account_series[account_series<250000] # boolean index
account_series[list(range(0, 15, 2))] # fancy index
# basic
df[["name", "street"]][:2] # 칼럼 이름과 인덱스 번호를 적어준다.
df.loc[[211829, 320563],["name","street"]] # 인덱스 번호를 먼저 적고 칼럼을 적어준다.
df.iloc[:2, :3] # 행2개, 칼럼3개
# 인덱스 변경
# 인덱스 변경
df.index = df["account"]
del df["account"]
df.head()
df.index = list(range(0, 15))
df.head()
# 인덱스를 새로 한줄 만든다.
df.reset_index()
# 인덱스를 새로 한줄 만들고, 기존 인덱스는 삭제한다.
df.reset_index(drop=True)
# 인덱스를 새로 한줄 만들고, 기존 인덱스는 삭제한다. 기존 df도 변경된다.
df.reset_index(inplace=True, drop=True)# 삭제
# 데이터 삭제
# 옵션으로 inplace=True를 주면 기존 데이터를 대체한다.
df.drop([0,1,2,3]) # 행삭제
df.drop("city", axis=1) # 열삭제# series operation


인덱스를 기준으로 연산을 수행하기 때문에 겹치는 index가 없는 경우에는 NaN이 결과에 넣어진다.
중복되는 index가 있는 경우에도 에러없이 모두 연산이 일어난다.

# dataframe operation



df는 column과 index를 모두 고려한다.
fill_value 옵션을 사용하면 nan값은 fill_value가 된다.
operation 종류로는 add, sub, div, mul이 있다.
# series 와 dataframe 간의 연산




# map for series
pandas의 series 데이터도 map 함수를 사용가능하다.




# replace function
map과 비슷하지만 데이터 변환 기능만 담당한다.
실제 값을 치환하는것은 아니고, 치환하려면 inplace=True 옵션을 주어야 한다.

# apply
칼럼 전체에 어떤 함수를 적용할 때 사용한다.
통계를 낼때 자주 사용된다.

mean이나 std등도 사용 가능하다.
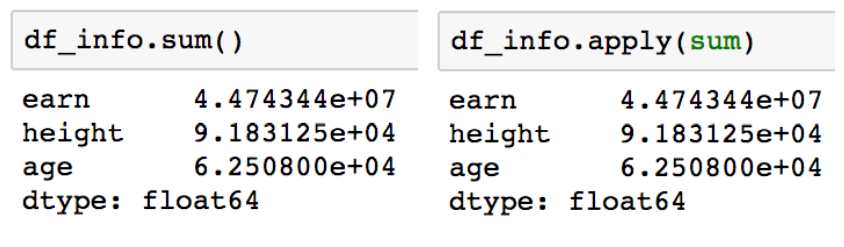

# apply map
시리즈 단위가 아닌 모든 element에 함수를 적용한다.

# describe
숫자로 된 데이터의 칼럼별로의 count, mean, std, min, max등의 요약된 정보를 보여준다.
# unique
시리즈 데이터에서 유일한 값으로 구성된 리스트를 반환한다.
# sum
axis=0 옵션일때는 칼럼별로의 합계를 보여주고(행을 쌓는 방향)
axis=1 옵션일때는 로우별로의 합계를 보여준다.(열을 쌓는 방향)
# isnull
column 또는 row 값의 index를 반환한다.
df.isnull().sum()과 같이 사용하면 null인 값의 갯수를 얻을 수 있다.
# sort_values
칼럼 값을 기준으로 데이터를 sorting 한다.
df.sort_values(["age", "earn"], ascending=True).head(10)
# correlation & covariance
상관계수와 공분산을 구하는 함수
df.age.corr(df.earn)
df.age.cov(df.earn)
df.corrwith(df.earn)
df.corr()
# 신경망
선형모델로는 해결할 수 있는 문제들이 한계가 있으므로, 비선형모델인 신경망이 사용된다.
행벡터 o(n*p)는 데이터 x(n*d)와 가중치 행렬 w(d*p)사이의 행렬곱과
y절편 b(n*p)벡터의 합으로 표현된다고 가정 할 수 있다.
b행렬은 모든 행이 같은, 복제된 행렬이다.
즉, 모든 행에 대해서 같은 값을 더해주는 것이다.
가중치 행렬을 행렬곱해주면서 n*d꼴의 데이터는 n*p꼴의 데이터로 변경된다.
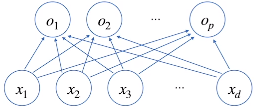
결론적으로는 데이터 x가 d개의 열을 가지고 있을때, 이 데이터로부터 p개의 선형 모델을 만드는 것이다.
# softmax
모델의 출력을 확률로 해석할 수 있게 변환해주는 연산이다.
분류 문제를 풀때 선형 모델과 소프트맥스 함수를 결합하여 예측한다.
softmax(o) = softmax(Wx + b)
# 활성함수
활성함수를 사용하지 않으면 딥러닝은 선형모형과 차이가 없다.
시그모이드 함수, tanh 함수를 전통적으로 많이 썼지만, 딥러닝에서는 ReLU함수를 주로 사용한다.

# 신경망
선형모델과 활성함수를 합성한 함수이다.

# 다층퍼셉트론
신경망이 여러층 합성된 함수

# 여러 층을 쌓는 신경망을 사용하는 이유

# 역전파 알고리즘


'ai tech' 카테고리의 다른 글
| ai tech 10일차 (0) | 2021.01.29 |
|---|---|
| ai tech 9일차 (0) | 2021.01.28 |
| ai tech 7일차 (0) | 2021.01.26 |
| ai tech 6일차 (0) | 2021.01.25 |
| ai tech 5일차 (0) | 2021.01.22 |