# 군집
다음 조건들을 만족하는 정점들의 집합이다.
1. 집합에 속하는 정점 사이에는 많은 간선이 존재한다.
2. 집합에 속하는 정점과 그렇지 않은 정점 사이에는 적은 수의 간선이 존재한다.
많고 적은 것이 모호하기 때문에 수학적으로 엄밀한 정의는 아니다.

# 실제 그래프에서의 군집
온라인 소셜 네트워크에서의 군집은 사회적 무리(social circle)들을 의미하는 경우가 많다.

부정행위와 관련된 경우도 있다.
트위터에서 부정행위와 관련된 계정은 다른 부정행위와 관련된 계정과 팔로우 되어있는 경우가 많다.

조직 내의 분란이 소셜 네트워크 상의 군집으로 표현되는 경우도 있다.
아래 그림에서 동아리가 두개 군집으로 나뉘어져 있다.

인접행렬으로 나타내게되면 0이 아닌값들이 몰려있는 것을 확인할 수 있다.
키워드-광고주 그래프에서는 동일한 주제의 키워드들이 군집을 형성한다.

뉴런간 연결 그래프에서는 군집들이 뇌의 기능적 구성 단위를 의미한다.
한 군집이 뇌의 특정 기능을 담당한다.

# 군집 탐색 문제
그래프를 여러 군집으로 잘 나누는 것을 군집 탐색 문제라고 한다.
보통은 각 정점이 한 개의 군집에 속하도록 군집을 나눈다.
비지도 기계학습 문제인 클러스터링 문제와 상당히 유사하다.
하지만 클러스터링 문제는 피쳐들의 벡터형태로 표현된 인스턴스들을 그룹으로 묶는다면,
군집 탐색 문제는 정점들을 묶는 것이다.
그렇다면 잘 묶는다는것은 무엇일까?
# 비교 대상: 배치모형
성공적인 군집 탐색은 비교를 통해서 정의되고,
비교의 대상이 되는 것이 배치모형이다.
주어진 그래프에 대한 배치모형은
1. 각 정점의 연결성을 보존한 상태에서
2. 간선들을 무작위로 재배치 하여 얻은 그래프를 의미한다
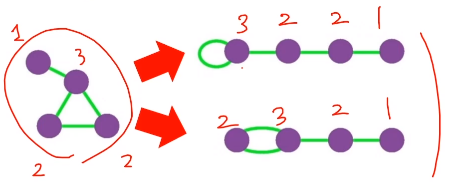
재배치 했더라도 이전과 연결성은 그대로이다.
간선들을 무작위로 재배치하였기 때문에,
배치모형에서 임의의 두 정점 i와 j 사이에 간선이 존재할 확률은
두 정점의 연결성에 비례한다.
# 군집성
군집 탐색의 성공 여부를 판단하기 위해서 군집성이 사용된다.
그래프와 군집의 집합 S가 주어졌다고 할때,
각각의 군집이 군집의 성질을 잘 만족하는지 살펴보기 위해
군집 내부 간선수를 그래프와 배치모형에서 비교한다.
군집성은 다음과 같이 계산한다.

앞에 분수로 인해 정규화 되고, -1와 1 사이의 값이 된다.
배치모형과 비교했을때,
그래프에서 군집 내부 간선의 수가 월등히 많을수록 성공한 군집 탐색이다.
즉, 군집성은 무작위로 연결된 배치모형과의 비교를 통해서 통계적인 유의성을 판단한다.
군집성은 항상 -1과 1 사이의 값을 갖느다.
군집성이 0.3~0.7정도의 값일때,
그래프에 존재하는 통계적으로 유의미한 군집을 찾아냈다고 할 수 있다.
# 군집 탐색 알고리즘
크게 두가지가 있다.
1. Girvan-Newman 알고리즘
2. Louvain 알고리즘
# Girvan-Newman 알고리즘
대표적인 하향식 군집 탐색 알고리즘이다.
전체 그래프에서 탐색을 시작하고,
군집들을 서로 분리되도록 간선을 순차적으로 제거한다.
서로 다른 군집을 연결하는 다리를 제거하는 것이다.

서로 다른 군집을 연결하는 다리 역할을 그러면 어떻게 찾을까
간선의 매개 중심성을 사용한다.
해당 간선이 정점간의 최단 경로에 놓이는 횟수가 매개 중심성이다.
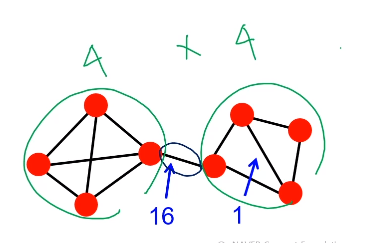
저 중간에 다리는 최단경로에 16번 속하지만,
오른쪽에 다리는 최단경로에 한번 속한다.

최단경로는 여러개가 있을 수 있는데, 특정 간선을 지나는 최단경로의 비율을, 모든 노드 쌍에 대해서 평균내는 것이다.
매개 중심성을 통해 서로 다른 군집을 연결하는 다리 역할의 간선을 찾아낼 수 있다.

Girvan-Newman 알고리즘은 매개 중심성이 높은 간선을 순차적으로 제거한다.
그리고 간선이 제거될 대마다 매개 중심성을 다시 계산하여 갱신한다.




모든 간선이 제거될때까지 반복된다.
간선의 제거 정도에 따라서 다른 입도(Granularity)의 군집 구조가 나타난다.

그러면 어느정도 간선을 제거하는 것이 적절할까?
군집성이 최대가 되는 지점까지 간선을 제거한다.
단, 현재의 연결 요소들을 군집으로 가정하되, 입력그래프에서 군집성을 계산한다.

알고리즘을 정리하면 다음과 같다.
1. 전체 그래프에서 시작한다.
2. 매개 중심성이 높은 순서로 간선을 제거하면서, 군집성의 변화를 기록한다.
3. 군집성이 가장 커지는 상황을 복원한다.
4. 그 상황에서의 서로 연결된 정점들, 연결 요소를 하나의 군집으로 간주한다.
전체 그래프에서 시작해서 점점 작은 단위로 검색하는 하향식 방법이다.
# Louvain 알고리즘
대표적인 상향식 군집 탐색 알고리즘이다.
개별 정점에서 시작해서 점점 큰 군집을 형성한다.


군집들을 합칠때는 군집성으로 합친다.
1. 개별 정점으로 구성된 크기 1의 군집들로부터 시작한다.

2. 각 정점을 기존 혹은 새로운 군집으로 이동한다.
이때, 군집성이 최대화되도록 군집을 결정한다.
3. 그리고 더이상 군집성이 증가하지 않을때까지 반복한다.

4. 군집을 하나의 정점으로 하는 군집 레벨 그래프를 얻은뒤 3의 과정을 반복한다.

5. 한 개의 정점이 남을때까지 4를 반복한다.


# 주중첩이 있는 군집 구조




현실의 경우에는 그래프는 주어지지만 중첩 군집 모형은 주어지지 않은 경우가 많다.
그래서 중첩 군집 탐색은 주어진 그래프의 확률을 최대화 하는 충접 군집 모형은 찾는것이다.

중첩 군집 탐색을 용이하게 하기 위해서 완화된 중첩 군집 모형을 사용한다.
완화된 중첩 군집 모형에서는 각 정점이 각 군집에 속해있는정도를 실수값으로 표현한다.
기존 모형에서는 각 정점이 각 군집에 속하거나 속하지 않거나였는데, 중간 상태를 표현하게 되는 것이다.

최적화 관점에서는 모형의 매개변수들이 실수 값을 가지기 때문에
익숙한 최적화 도구를 사용하여 모형을 탐색할 수 있다는 장점이 있다.
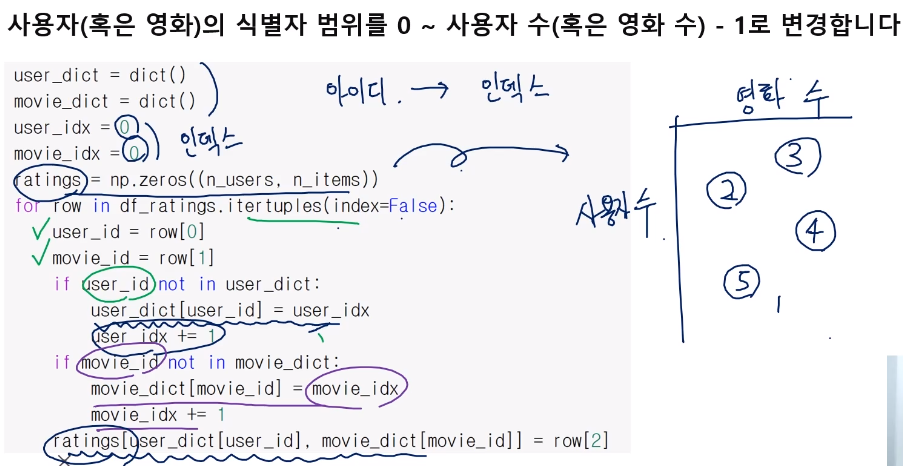
# Girvan-newman 알고리즘 구현


이 알고리즘은 간선을 끊어가기 때문에, 최초의 그래프를 백업해둔다.
step은 이터레이션
logModularityList는 군집성을 기록하는 용으로 사용한다.
maxModCom은 군집성이 최고가 되는 지점에서의 커뮤니티 정보를 저장한다.
maxMod는 군집성이 최고가 된 상태에서의 군집성 값을 저장한다.
maxStep은 군집성이 최고가 된 상태에서의 이터레이션을 기록한다.








# 아마존에서의 상품 추천
고객이 살만한 상품 목록을 보여준다.
함께 혹은 대신 구매할 상품 목록을 보여준다.
# 넷플릭스에서의 영화 추천
고객 맞춤형 영화 목록을 보여준다.
# 유투브에서의 영상 추천
고객이 좋아할만한 영상, 관련 영상들을 보여준다.
# 페이스북에서의 친구 추천
알만한 사람들을 추천해준다.
# 추천시스템과 그래프
추천 시스템은 사용자 각각이 구매할만 한 상품, 영화, 영상을 추천한다.
추천 시스템의 핵심은 사용자별 구매를 예측하거나 선호를 추정하는 것이고,
그래프 관점에서 추천 시스템은 미래의 간선을 예측하는 문제, 누락된 간선의 가중치를 추정하는 문제로
변경해서 생각할 수 있다.

# 내용 기반 추천시스템의 원리
사용자가 구매했던, 만족했던 상품과 유사한 것을 추천하는 방법이다.








로맨스 영화를 몇번 봤다고 해서, 로맨스 영화만 추천해주는 결과를 초래할 수도 있다.
# 협업 필터링









# 추천 시스템의 평가




# 협업 필터링 구현